
Introduction
libgdata is a library to allow access to web services using the GData protocol from the desktop. The GData protocol is a simple protocol for reading and writing data on the web, designed by Google.
Protocols
Google's services were originally only accessible using an XML-based protocol called GData. However, later additions to the set of available services use a REST-style JSON protocol. libgdata supports both protocols, although specific services use exactly one of the two protocols.
The core API in libgdata transparently supports both protocols, so client code need not consider which protocol to use.
XML protocol
The GData XML protocol is designed by Google to allow interaction with their web services. It is based on the Atom Publishing protocol, with namespaced XML additions. Communication between the client and server is broadly achieved through HTTP requests with query parameters, and Atom feeds being returned with result entries. Each service has its own namespaced additions to the GData protocol; for example, the Google Calendar service's API has specialisations for addresses and time periods.
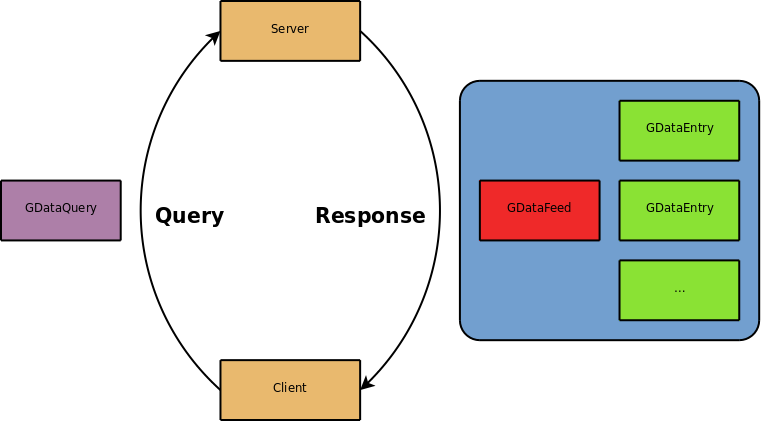
Results are always returned in the form of result feeds, containing multiple entries. How the entries are interpreted depends on what was queried of the service, but when using libgdata, this is all taken care of transparently.
JSON protocol
The more recent JSON protocol is similar in architecture to the XML protocol: entries are arranged into feeds, and the core operations available are: listing all entries, getting a specific entry, inserting an entry, updating an entry and deleting an entry.
The key difference between the two protocols, apart from the serialisation format, is that the JSON protocol is not namespaced. Each service uses a specific JSON format, and there is no formal sharing of data structures between services. For example, every entry in the XML protocol is required to have a title, ID and update time (as per the Atom specification). Such commonality between JSON entries is purely ad-hoc.
Differences between the XML and JSON protocols are hidden by the libgdata API. Both protocols are implemented by the standard GDataService, GDataFeed and GDataEntry classes.
Structure
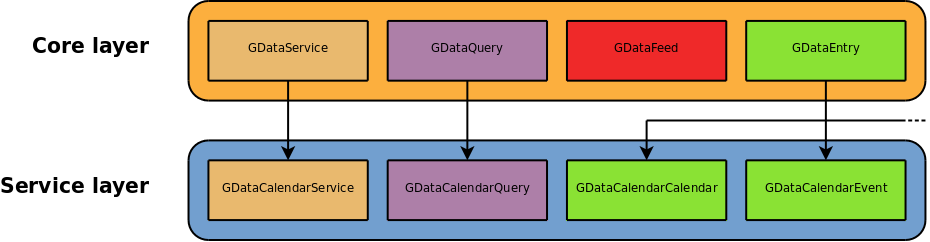
The basic design of libgdata mirrors the protocol's structure quite closely:
|
Subclassed for each different web service implemented, this class represents a single client's connection to the relevant web service, holding their authentication state, and making the necessary requests to read and write data to and from the service. All top-level actions, such as creating a new object on the server, are carried out through a service. There should be one GDataService subclass for each of the services listed in the GData documentation. |
|
|
For queries to have multiple individual parameters, a GDataQuery can be used to specify the parameters. Query objects are optional, and can only be used with queries (not with entry insertions, updates or deletions). The query object builds the query URI used by the GDataService when sending the query to the server. Services can subclass GDataQuery if the service supports non-standard query parameters. |
|
|
Effectively a list of GDataEntrys, the GDataFeed class is a direct counterpart of the root <feed> element in the Atom feeds which form the GData protocol. It contains the elements in a query response, as well as general information about the response, such as links to related feeds and the categories under which the query response falls. GDataFeed is usually not subclassed by services, as there are rarely service-specific elements in a feed itself. |
|
A GDataEntry is a direct counterpart of the <entry> element in the Atom feeds which form the GData protocol. It represents a single object of unspecified semantics; an entry could be anything from a calendar event to a video comment or access control rule. Semantics are given to entries by subclassing GDataEntry for the various types of entries returned by queries to a service. Such subclasses implement useful, relevant and query-specific properties on the entry (such as the duration of a video, or the recurrence rules of a calendar event). |
Development Philosophy
As the GData protocol (and all the service-specific protocols which extend it) is reasonably young, it is subject to fairly frequent updates and expansions. While backwards compatibility is maintained, these updates necessitate that libgdata remains fairly flexible in how it treats data. The sections below detail some of the ways in which libgdata achieves this, and the reasoning behind them, as well as other major design decisions behind libgdata's API.
Enumerable Properties
There are many class properties in libgdata which should, at first glance, be implemented as enumerated types. Function
calls such as gdata_link_get_relation_type()
and gdata_gd_im_address_get_protocol()
would, in a conventional library, return a value from an enum, which would work well, and be more typesafe and
memory-efficient than using arbitrary strings.
However, such an implementation would not be forwards-compatible. If a protocol addition was made which added another link relation type, or added supportf or another IM protocol, there would be no way for libgdata to represent some of the data it retrieved from the server. It could return an “other” value from the enum, but that could lead to data loss in the common case of GData entries being queried from the server, processed, then updated again.
For this reason – which is made more troublesome by the fact that it is unpredictable when updates to the protocol are
released, or when updated XML/JSON will start coming over the wire – libgdata uses enumerated types sparingly; they are
only used when it is very improbable (or even impossible) for the property in question to be extended or changed in
the future. In any other case, a string value is used instead, with libgdata providing #defined values
for the known values of the property. These values should be used as much as possible by applications which use
libgdata (i.e. they should be treated as if they were enumerated values), but applications are free to use strings
of their own, too. All validation of such pseudo-enums is left to the server.
One situation where it is acceptable to use enumerated types is in API which is only ever used to query the server, and isn't involved in processing or representing the response at all, i.e. subclasses of GDataQuery.
String Constants
As the protocols are XML- or JSON-based, they make extensive use of string constants, typically as
enumerated types or namespaced URIs. To stop the authors of applications
which use libgdata from having to continually look up the correct “magic strings” to use, all such strings should
be #defined in libgdata, and referenced in the appropriate function documentation.
New Services
The API required to implement support for a new service using libgdata is not publicly exposed. This is because doing so would clutter the API to a large extent; for example, exposing various properties as writeable which are currently only readable. While the freedom for users of libgdata to write their own services is a good one, it is outweighed by the muddlement that this would bring to the API.
Furthermore, since it is highly unlikely that anyone except Google will use GData as a basis for communicating with their service, there is little harm in restricting the implementation of services to libgdata. If someone wants to implement support for a new GData service, it is for the benefit of everyone if this implementation is done in libgdata itself, rather than their application.
Cancellable Support
As libgdata is a network library, it has to be able to deal with operations which take a long (and indeterminate) amount of time due to network latencies. As well as providing asynchronous operation support, every such operation in libgdata is cancellable, using GCancellable.
Using GCancellable, any ongoing libgdata operation can be cancelled
from any other thread by calling g_cancellable_cancel.
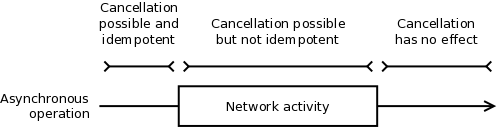
If the ongoing operation is doing network activity, the operation will be cancelled as safely as possible (although
the server's state cannot be guaranteed when cancelling a non-idempotent operation, such as an insertion or update,
since the server may have already committed the results of the operation, but might not have returned them to libgdata
yet) and the operation will return to its calling function with a
G_IO_ERROR_CANCELLED error. Similarly,
if the operation is yet to do network activity, it will return with the above error before the network activity is
started, leaving the server unchanged.
However, if the operation has finished its network activity, libgdata does not guarantee that it will return with an error — it may return successfully. There is no way to fix this, as it is an inherent race condition between checking for cancellation for the last time, and returning the successful result. Rather than reduce the probability of the race condition occurring, but still have the possibility of it occurring, libgdata will just continue to process an operation after its network activity is over, and return success.
This may be useful in situations where the user is cancelling an operation due to it taking too long; the application using libgdata may want to make use of the result of the operation, even if it has previously tried to cancel the operation after network activity finished.
The behaviour of cancellation in libgdata can be represented as follows:
Privacy
Privacy is an important consideration with code such as libgdata's, which handles valuable data such as people's address books and Google Account login details.
Unfortunately, it's infeasible for libgdata to ensure that no private data is ever leaked from a process. To do this properly would require almost all the data allocated by libgdata (and all the libraries it depends on, all the way down to the TLS implementation) to use non-pageable memory for all network requests and responses, and to be careful about zeroing them before freeing them. There isn't enough support for this level of paranoia in the lower levels of the stack (such as libsoup).
However, it is feasible to ensure that the user's password and authentication/authorization tokens aren't leaked. This is done in several ways in libgdata:
-
If libgdata is compiled with libgcr support enabled (using the
--enable-gnomeconfiguration flag), it will use libgcr's support for non-pageable memory. This will try hard to avoid passwords and auth. tokens being paged out to disk at any point (although there are circumstances, such as when hibernating, where this is unavoidable).Otherwise, libgdata will ensure that passwords and auth. tokens are zeroed out in memory before being freed, which lowers the chance of them reaching disk at a later stage.
Unless run with
LIBGDATA_DEBUGset to4, libgdata will attempt to redact all usernames, passwords and auth. tokens from debug log output. This aims to prevent accidental disclosure of passwords, etc. in bug reports. Currently, this is implemented using a fixed set of search patterns, so it's possible that certain bits of private information will not be redacted; any such occurrence is a bug which should be reported on GNOME Bugzilla.
libgdata universally uses HTTPS rather than HTTP for communicating with servers. The port which is used may be changed
for testing purposes, using the LIBGDATA_HTTPS_PORT environment variable; but the protocol used will
always be HTTPS.
libgdata provides ways to upload and download files, but does not implement code for loading or saving those files to or from disk. Since these files will typically be user data (such as their Google Drive documents), it is highly recommended that they are given restricted permissions, any temporary files are only readable by the current user, and files are potentially encrypted on disk where appropriate. The aim is to avoid leaking user data to other users of the system, or to attackers who gain access to the user’s hard drive (which may not be encrypted). libgdata itself only guarantees that data is encrypted while being sent over the network.